第 30 章
建立哈尔特征分类器 - 车牌辨识
正样本与负样本图像资料 · Haar 训练工具 · 样本标记 · 车牌侦测
第 27 章笔者介绍了 OpenCV 所提供的哈尔 (Haar) 特征分类器资源档案,侦测物件,这一节将以程式实例带领读者自行设计哈尔 (Haar) 特征分类器档案,一步一步做辨识台湾汽车车牌。
30-1
准备正样本与负样本图像资料
这一章的内容是要建立可以辨识汽车车牌的哈尔 (Haar) 特征分类器资源档案,这时必须准备 2 类图像,其中含汽车车牌的图像我们可以称正 (Positive) 样本图像,不含汽车车牌的图像称负 (Negative) 样本图像。
30-1-1 准备正样本图像 - 含汽车车牌图像
首先我们要准备汽车车牌,这些图像资料又称正样本图像,如下方左图所示,然后我们期待可以设计程式将车牌框选,可以参考下方右图。
目前台湾的汽车车牌有新式,相当然有 7 码与 6 码,为了单纯化笔者选择使用 7 码当作车牌辨识的样本图像。许多车牌辨识的停车场会将摄影机架在车身引擎盖相同的高度或是略高一点,所以我们在拍摄汽车图像时,最好也是如此,建议拍摄汽车图像时注意下列三点:
- 固定高度。
- 固定距离。
- 光线良好,可以清楚显示车身与车牌。
也就是我们模拟停车场的摄影机镜头,但是拍摄时很担心被路人或车主撞见,被怀疑有不良企图,因此笔者所准备的图像无法保持一定高度与距离,本章实例笔者只准备了约 50 张图像,部分图像则是相同图像裁剪不同部位而成,最后处理成 90 张图像。
30-1-2 准备负样本图像 - 不含汽车车牌图像
所谓的负样本图像就是指不含汽车车牌的图像,由于我们要训练电脑可以认识汽车车牌,所以要准备一系列不含汽车车牌的图像告诉系统这些图像是不含汽车车牌,这些图像最好是包罗万象,越多越好,本书笔者准备了约 295 张图像。
建议读者学会本章内容后,可以准备 1000 张以上的图像。
30-2
处理正样本图像
这本书笔者将原始拍摄的图像放在 ch30/srcCar 资料夹,如下所示:
30-2-1 将正样本图像处理成固定宽度与高度
停车场的摄影机由于固定在入口位置,所以可以保持一定高度与距离拍摄车辆,最后可以取得固定大小的图像,我们的图像是用手机拍摄,高度与距离无法完全相同,所以只能使用裁剪方式处理正样本图像。
程式实例 ch30_1.py:将所有在 ch30/srcCar 资料夹的档案,处理成宽与高分别是 320 和 240 像素的图像,然后储存在 ch30/dstCar 资料夹。
# ch30_1.py
import cv2
import os
import glob
import time
import shutil
srcDir = "srcCar"
dstDir = "dstCar"
width = 320
height = 240
if os.path.isdir(dstDir): # 检查是否存在
# 因为 dstCar 资料夹可能含资料,所以使用 shutil.rmtree() 函数删除
shutil.rmtree(dstDir) # 先删除资料夹
time.sleep(3) # 休息让系统处理
os.mkdir(dstDir) # 建立资料夹
cars = glob.glob(srcDir + "/*.jpg") # 取得资料夹下所有汽车图像名称
print(f"执行{srcDir}资料夹内修改尺寸的汽车图像")
for index, car in enumerate(cars): # 依序取出所有档案
img_car = cv2.imread(car, cv2.IMREAD_COLOR) # 读取车辆图像
img_car_resize = cv2.resize(img_car, (width, height))
car_name = "car" + str(index) + ".jpg" # 车辆图像命名
fullpath = dstDir + "\\" + car_name
print(f"储存{dstDir}资料夹内修改尺寸的图像。")
cv2.imwrite(fullpath, img_car_resize) # 写入车辆图像
==================== RESTART: D:\OpenCV_Python\ch30\ch30_1.py ====================
执行srcCar资料夹内修改尺寸的汽车图像
储存dstCar资料夹内修改尺寸的图像。
开启 ch30/dstCar 资料夹可以得到下列结果,同时每张图像宽与高分别是 320 和 240。
30-2-2 将正样本图像转成 bmp 档案
为了要记录我们建立哈尔分类器的过程,所以笔者采用逐步说明,使用不同资料夹储存每一阶段的执行结果。在讲解程式实例 ch30_3.py 之前,笔者先介绍将含路径的字串拆成资料夹与档案名称。
程式实例 ch30_2.py:读取所有 dstCar 资料夹的档案,将档案串列的路径与档案名称拆开。
# ch30_2.py
import os
import glob
dstDir = "dstCar"
allcars = dstDir + "/*.jpg" # 建立档案模式
cars = glob.glob(allcars) # 获得档案名称
print(f"目前资料夹档案名称 = \n{cars}") # 列印档案名称
# 拆解资料夹符号
for car in cars:
carname = car.split("\\") # 将字串转成串列
print(carname)
==================== RESTART: D:\OpenCV_Python\ch30\ch30_2.py ====================
目前资料夹档案名称 =
['dstCar\\car1.jpg', 'dstCar\\car10.jpg', 'dstCar\\car11.jpg', ...,
'dstCar\\car89.jpg', 'dstCar\\car9.jpg', 'dstCar\\car90.jpg']
['dstCar', 'car1.jpg']
['dstCar', 'car10.jpg']
['dstCar', 'car11.jpg']
了解上述程式后,读者可以比较容易了解下列程式。
程式实例 ch30_3.py:将所有 ch30/dstCar 资料夹内的 .jpg 汽车图像转成 .bmp 图像,同时存入 ch30/bmpCar 资料夹。
# ch30_3.py
import cv2
import os
import glob
import time
import shutil
dstDir = "dstCar"
bmpDir = "bmpCar"
if os.path.isdir(bmpDir): # 检查是否存在
# 因为 bmpDir 资料夹可能含资料,所以使用 shutil.rmtree() 函数删除
shutil.rmtree(bmpDir) # 先删除资料夹
time.sleep(3) # 休息让系统处理
os.mkdir(bmpDir) # 建立新资料夹
allcars = dstDir + "/*.jpg" # 建立档案模式
cars = glob.glob(allcars) # 获得档案名称
# print(f"目前资料夹档案名称 = \n{cars}") # 列印档案名称
# 拆解资料夹符号
for car in cars:
carname = car.split("\\") # 将字串转成串列
# print(carname)
car_img = cv2.imread(car, cv2.IMREAD_COLOR) # 读车子图像
outname = carname[1].replace(".jpg", ".bmp") # 将 jpg 改为 bmp
fullpath = bmpDir + "\\" + outname # 完整档名
cv2.imwrite(fullpath, car_img) # 写入资料夹
print("在 bmpCar 资料夹重新命名车辆副档名成功")
==================== RESTART: D:\OpenCV_Python\ch30\ch30_3.py ====================
在 bmpCar 资料夹重新命名车辆副档名成功
30-3
处理负样本图像
如前所述负样本图像就是不要含有汽车的图像,但是可以有与汽车相关的图像,例如:车道。当然为了能让我们哈尔 (Haar) 分类器可以辨识哪些图像是不含汽车,所以负样本图像也是越丰富越好,在实务上建议有 1000 张以上的图像,这些图像必须转成灰阶色彩,同时负样本图像宽与高必须大于正样本图像。
笔者准备的负样本图像储存在 ch30/notCar 资料夹。
程式实例 ch30_4.py:将 ch30/notCar 资料夹的所有负样本图像转为灰阶,档案名称改为 notcar*.jpg,同时将宽与高改为 500 和 400,然后存至 ch30/notCarGray 资料夹。
# ch30_4.py
import cv2
import os
import glob
import shutil
import time
srcDir = "notCar"
dstDir = "notCarGray"
width = 500 # 负样本宽
height = 400 # 负样本高
if os.path.isdir(dstDir): # 检查是否存在
# 因为 notCarDir 资料夹可能含资料,所以使用 shutil.rmtree() 函数删除
shutil.rmtree(dstDir) # 先删除资料夹
time.sleep(3) # 休息让系统处理
os.mkdir(dstDir) # 建立新资料夹
allcars = srcDir + "/*.jpg" # 建立档案模式
cars = glob.glob(allcars) # 获得档案名称
for index, car in enumerate(cars, 1):
img = cv2.imread(car, cv2.IMREAD_GRAYSCALE) # 灰阶读车子图像
img_resize = cv2.resize(img, (width, height)) # 调整负样本图像
imgname = "notcar" + str(index)
fullpath = dstDir + "\\" + imgname + ".jpg"
cv2.imwrite(fullpath, img_resize)
print("在 notCar 资料夹将图像转为灰阶成功,同时存入notCarGray资料夹")
==================== RESTART: D:\OpenCV_Python\ch30\ch30_4.py ====================
在 notCar 资料夹将图像转为灰阶成功,同时存入notCarGray资料夹
下列是原先的 ch30/notCar 资料夹内容。
下列是执行结果 ch30/notCarGray 资料夹内容。
30-4
建立辨识车牌的哈尔 (Haar) 特征分类器
30-4-1 下载建立哈尔特征分类器工具
请进入下列网址。
https://github.com/sauhaardac/haar-training
然后可以看到下列网页内容。
请点选 Code 内的 Download ZIP,可以下载 Haar-Training-master.zip 档案,请解压缩这个资料夹,可以得到 Haar-Training-master 资料夹,这个资料夹的资源主要是可以建立哈尔特征分类器,由于目前是要建立车牌辨识,所以笔者将资料夹名称改为 Haar-Training-car-plate。本书所附程式档案已经有这个资料夹了,所以读者可以省略下载步骤。
30-4-2 储存正样本图像
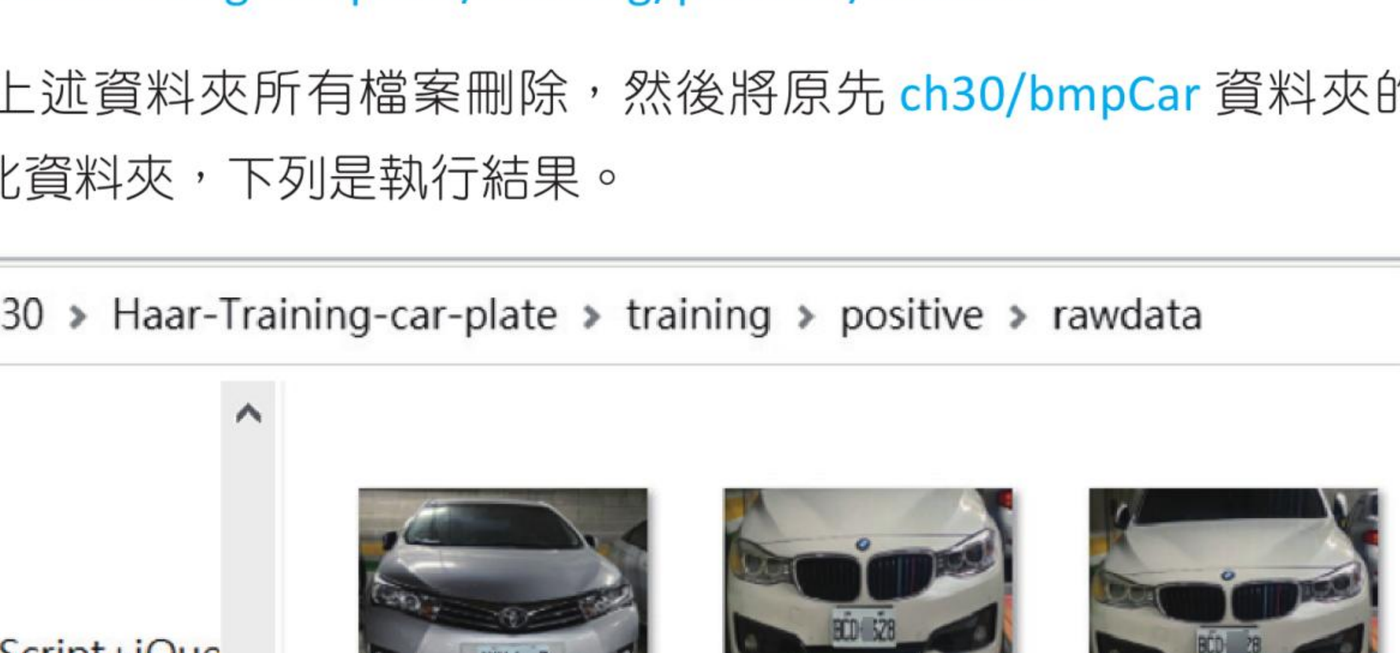
正样本图像必须储存在下列资料夹:
ch30/Haar-Training-car-plate/training/positive/rawdata
请先将上述资料夹所有档案删除,然后将原先 ch30/bmpCar 资料夹的所有 bmp 图像拷贝至此资料夹,下列是执行结果。
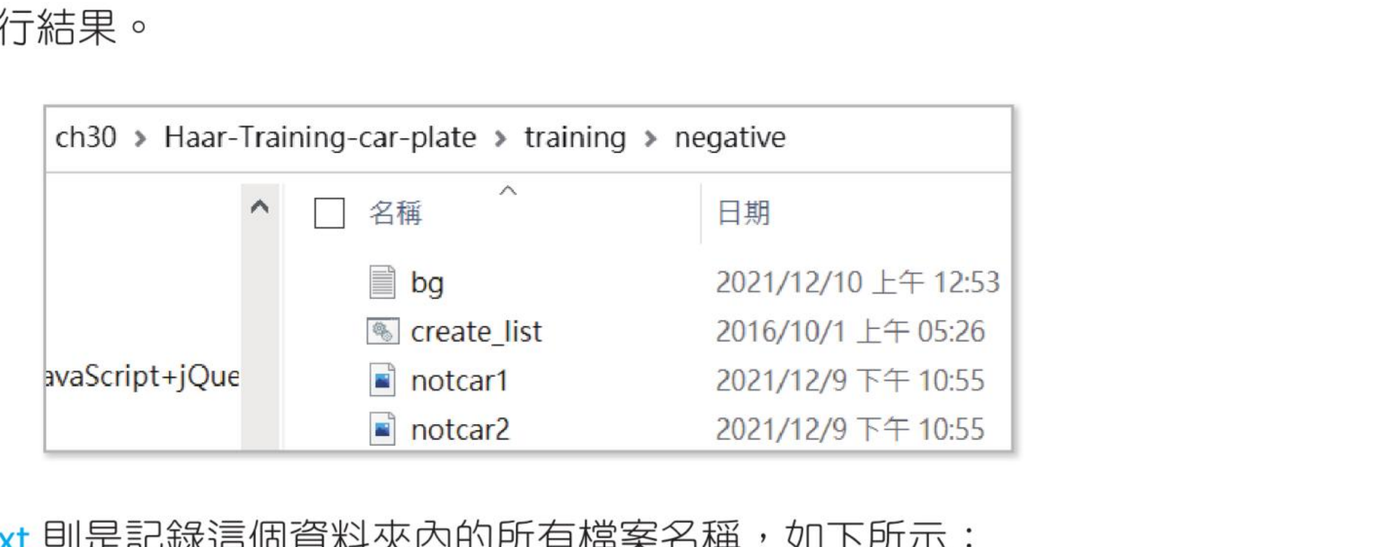
30-4-3 储存负样本图像
负样本图像是储存在下列资料夹:
ch30/Haar-Training-car-plate/training/negative
请执行下列步骤:
- 先将上述资料夹所有图像档案和
bg.txt 档案删除。
- 只保留
create_list.bat。
- 将程式实例 ch30_4.py 所建立的
ch30/notCarGray 资料夹内所有灰阶图像复制至此资料夹。
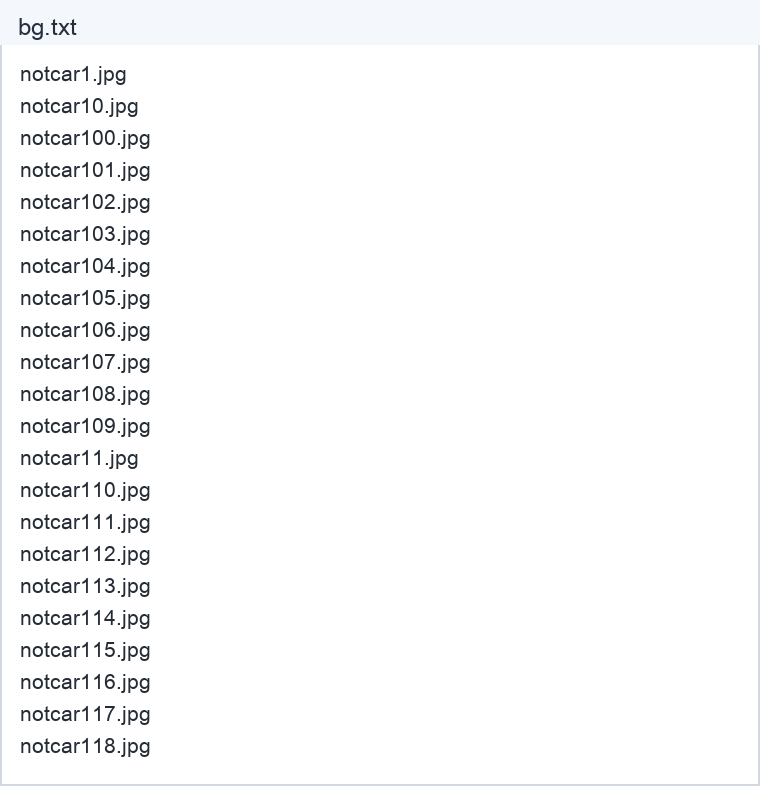
档案 create_list.bat 是批次档,主要是建立 bg.txt,连接两下可以建立此 bg.txt 档案,下列是执行结果。
上述建立 bg.txt 则是记录这个资料夹内的所有档案名称。
30-4-4 为正样本加上标记
我们必须告诉分类器所要侦测的物件,所以为正样本加上标记就是要将分类器辨识的物件标记出来,我们想要辨识汽车车牌,所以标记的方式是使用框选汽车图像的车牌。
开启 Haar-Training-car-plate/training/positive 资料夹内的 objectmarker.exe 档案,连接两下可以开启正的汽车样本图像,然后为每部车子的车牌加上外框,这个加外框的动作也称标记,标记方式如下:
- 将滑鼠标移至车牌左上角,拖曳至车牌右下角,可以建立车牌框。
- 同时按空白键和 Enter,可以自动出现下一辆车的图像。
上述框选完车牌后请同时按空白键和 Enter,可以看到所框选的左上角座标和 width 与 height,同时显示下一部车供框选。
标记完成后,在相同的资料夹中可以看到 info.txt 档案,这个档案纪录正样本图像的路径与档名、标记数量、标记座标、宽与高。
rawdata/car1.bmp 1 133 177 76 27
rawdata/car10.bmp 1 134 148 86 38
rawdata/car101.bmp 1 113 172 114 34
rawdata/car12.bmp 1 143 182 72 30
rawdata/car13.bmp 1 119 180 96 28
30-4-5 设计程式显示标记
前一节我们为每个正样本图像建立标记了,现在可以使用程式了解所建立的正样本图像标记,如果感觉位置有偏差可以修订 info.txt 的内容。
注意:如果重新执行 objectmarker.exe 会造成原先的标记消失。
程式实例 ch30_5.py:显示以及绘制车牌框线,读者可以在 ch30/plate-mark 资料夹看到所有框选的结果。
# ch30_5.py
# 标记检查
import cv2
import os
import shutil
import time
dstDir = "plate-mark"
path = "Haar-Training-car-plate/training/positive/"
if os.path.exists(dstDir): # 检查是否存在
shutil.rmtree(dstDir) # 删除资料夹
time.sleep(3) # 休息让系统处理
os.mkdir(dstDir)
fn = open(path + 'info.txt', 'r')
row = fn.readline() # 读取 info.txt
while row:
msg = row.split(' ') # 分割每一列文字
img = cv2.imread(path + msg[0]) # 读取档案
for i in range(int(msg[1])):
x = int(msg[2 + i * 4]) # 取得左上方 X 座标
y = int(msg[3 + i * 4]) # 取得左上方 Y 座标
w = int(msg[4 + i * 4]) # 取得 width 宽度
h = int(msg[5 + i * 4]) # 取得 height 高度
cv2.rectangle(img, (x, y), (x+w, y+h), (255, 0, 0), 2)
imgname = (msg[0].split('/'))[-1] # 使用 -1 是确定最右索引
print(imgname) # 输出处理过程
cv2.imwrite(dstDir + "\\" + imgname, img)# 写入资料夹
row = fn.readline()
fn.close()
print("绘制车牌框完成")
==================== RESTART: D:\OpenCV_Python\ch30\ch30_5.py ====================
car1.bmp
car10.bmp
car11.bmp
car12.bmp
car13.bmp
...
car88.bmp
car89.bmp
car9.bmp
car90.bmp
绘制车牌框完成
开启 ch30/plate-mark 资料夹看到所有框选的结果。
30-5
训练辨识车牌的哈尔特征分类器
30-5-1 建立向量档案
正样本图像必须打包为向量档案才可以进行训练,首先请编辑 ch30/Haar-Training-car-plate/training 资料夹的 samples_creation.bat,请参考下列修改内容:
createsamples.exe -info positive/info.txt -vec vector/facevector.vec -num 90 -w 70 -h 20
上述内容与意义如下:
createsamples.exe:打包向量档案的程式。-info positive/info.txt:positive/info.txt 是正样本标记的路径。-vec vector/facevector.vec:建立向量档的路径和档案名称。-num:正样本图像的数量。-w:侦测标记的宽度。-h:侦测标记的高度。
连按两下 samples_creation.bat 可以在 vector 资料夹建立 facevector.vec 向量档案,下列是执行结果。
30-5-2 训练哈尔分类器
请删除 ch30/Haar-Training-car-plate/training/cascades 资料夹内容。请编辑 ch30/Haar-Training-car-plate/training 资料夹的 haartraining.bat,这是批次档,请参考下列修改内容:
haartraining.exe -data cascades -vec vector/facevector.vec -bg negative/bg.txt -npos 90 -nneg 295 -nstages 15 -mem 512 -mode ALL -w 70 -h 20 -nonsym
上述内容与意义如下:
haartraining.exe:训练哈尔分类器的执行档程式。-data cascades:data 是指未来要储存训练结果的资料夹,cascades 是储存结果的资料夹。-vec vector/facevector.vec:vec 是指正样本的向量档案。-bg negative/bg.txt:bg 是指负样本的档案。-npos 90:npos 是指正样本的数量。-nneg:nneg 是指负样本的数量。-nstages:nstages 是指训练的级数,一般训练级数越多所需时间越多,一般可以设定在 12 ~ 20 之间。-mem:哈尔特征训练资料所需的记忆体,记忆体越大所需时间越多。-mode:哈尔特征的训练模式,BASIC 是标准特征、CORE 是线性和核心特征、ALL 是使用所有特征。-w、-h:侦测物件的宽度与高度。-nonsym:侦测物件使用非对称方式,如果想要使用对称方式可以设为 sym。
然后连点此批次档两下,执行此档案,当看到下列画面表示开始训练资料。
Number of features used: 958635
Parent node: NULL
*** 1. cluster ***
POS: 70 1.000000
NEG: 295
BACKGROUND PROCESSING TIME: 0.01
precalculation time: 8.89
+----+---------+-----------+----------+----------+----------+
| N | XMSF | ST.THR | HR | FA | ERR |
+----+---------+-----------+----------+----------+----------+
| 1 | 1 | -0.942940 | 1.000000 | 1.000000 | 0.027387 |
训练结束后,可以在 ch30/Haar-Training-car-plate/training/cascades 资料夹看到下列训练结果。
30-5-3 建立哈尔特征分类器资源档
请编辑 ch30/Haar-Training-car-plate/cascade2xml 资料夹的 convert.bat 档案,内容如下:
haarconv.exe ../training/cascades ../../haar_carplate.xml 70 20
上述 ../ 代表上一层资料夹,其他内容与意义如下:
haarconv.exe:建立哈尔特征分类器资源档所需要的可执行档案。../training/cascades:哈尔特征分类器的训练结果资料夹。../../haar_carplate.xml:要建立的哈尔特征分类器资源档。70 20:侦测物件的宽度和高度。
30-6
车牌侦测
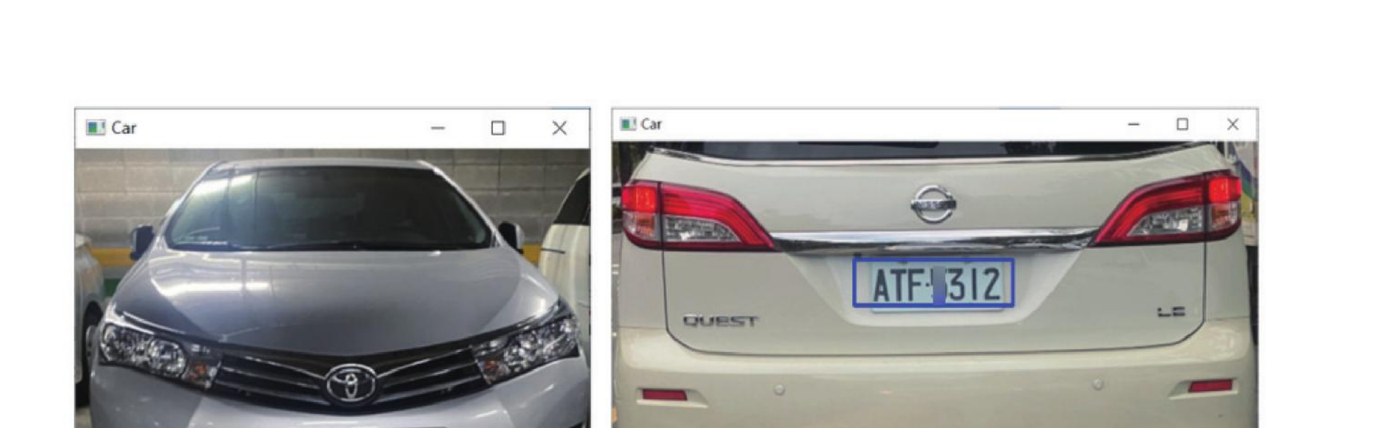
现在就可以使用第 27 章的观念侦测车牌,在 ch30/testCar 资料夹有 3 个供测试的汽车图像,分别是 cartest1.jpg、cartest2.jpg 和 cartest3.jpg。
程式实例 ch30_6.py:侦测 cartest1.jpg 车牌的实例。
# ch30_6.py
import cv2
pictPath = "haar_carplate.xml" # 哈尔特征路径
img = cv2.imread("testCar/cartest1.jpg") # 读辨识的图像
car_cascade = cv2.CascadeClassifier(pictPath) # 读哈尔特征档
# 执行辨识
plates = car_cascade.detectMultiScale(img, scaleFactor=1.05, minNeighbors=3,
minSize=(20, 20), maxSize=(155, 50))
if len(plates) > 0: # 有侦测到车牌
for (x, y, w, h) in plates:
cv2.rectangle(img, (x, y), (x+w, y+h), (255, 0, 0), 2) # 标记车牌
print(plates)
else:
print("侦测车牌失败")
cv2.imshow("Car", img) # 显示所读取的车辆
cv2.waitKey(0)
cv2.destroyAllWindows()
==================== RESTART: D:/OpenCV_Python/ch30/ch30_6.py ====================
[[193 338 146 42]]
下列两张图像分别是 ch30_6_1.py 和 ch30_6_2.py 测试 cartest2.jpg 和 cartest3.jpg 的结果。
30-7
心得报告
这一个章节笔者讲解建立车牌辨识哈尔分类器的整个步骤,经过测试其实辨识率仍有待加强,主要原因如下:
- 拍摄车牌时笔者没有固定距离与高度。
- 车牌样本数不足,建议至少 500 张不同车辆图像。
- 负样本数量仍不够多,其实也应该多准备一些与车辆有关的图像(但是不含车辆),例如:道路图像。建议至少 500 张不同的负样本图像。
习题
1. 请参照 30-7 节的心得修订与改良本书的 haar_carplate.xml 哈尔特征分类器档案。
注:这一题没有附习题解答。